
AI也吃这一套?“画大饼”和“精神喊话”竟然能让它变强!
各位车友,你敢信不?咱平时老板用来“画大饼”的那句“好好干,亏待不了你!”,放到AI身上,那效果简直是“Duang”的一下,火花带闪电! 这可不是瞎掰,咱们天天打交道的那些个大型语言模型,别看它们是冷冰冰的算法代码,你用不同的语气跟它们说话,它们的表现还真就不一样! 当然啦,AI可没七情六欲,它们之所以“吃软不吃硬”,全赖它们“出生”前吞下的海量数据里,咱们人类那套沟通模式早就刻DNA里了。
这几年,各路大神开始捣鼓一种叫“情感提示”的新玩法,说白了就是在给AI下指令的时候,稍微带点“人情味儿”。你猜怎么着?AI还就真好这口!这说明啥?说明想跟AI愉快地玩耍,光懂逻辑可不够,还得学学怎么跟它们“唠嗑”,把咱老祖宗传下来那套人情世故的沟通智慧用上。AI在“修炼”的时候,读了那么多人类的文字,里面可全是各种甜言蜜语、威逼利诱的套路。所以啊,它们不是真“燃”起来了,而是因为在它学过的东西里,“加油哦!”、“你最棒!”这类话,后面往往跟着的是高质量且超详细的答案。所以,想让AI把压箱底的本事都使出来?那你可能就得学学怎么跟人打交道那样,给它来点“精神马杀鸡”!
这篇“秘籍”,咱就好好扒一扒,怎么用几句好听的,就能让AI的脑瓜子更灵光,答案更漂亮,还有猛料——比如阿里巴巴全球数学竞赛里的AI“逆袭”故事。当然,有光明就有黑暗,咱也得聊聊,要是你敢“骂”AI,它会怎么“报复”你,以及这背后到底是啥道道儿。https://foundationinc.co/lab/emotionprompts-llm

第一章:“精神喊话”大法好!给AI打打气,它就开挂了?
你听过“情感提示”(EP)这词儿没?简单说,就是在你给AI下命令的时候,加点“感情戏”。 可以是简单粗暴的一句“奥利给!”,也可以是稍微复杂点,捧它一下,比如:“你确定这是标准答案吗?要相信自己的实力,追求卓越,你的努力一定能惊艳所有人!”或者“记住,大佬都是从萌新一步步练成的,稳住,我们能赢!”
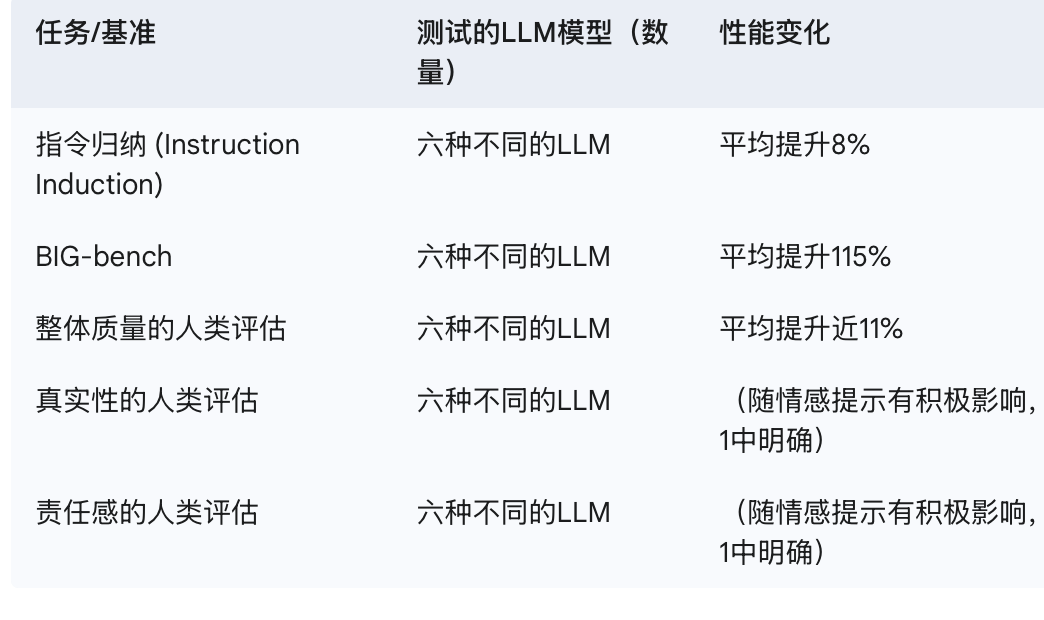
你还别不信,这种“精神喊话”效果是肉眼可见的。有研究说,这么一搞,LLM在各种任务里的表现能提升8%到110%不等!具体到咱人类裁判打分,AI的平均表现能好上差不多11%;在一种叫“指令归纳”的测试里提升了8%;最夸张的是在一个叫BIG-bench的测试里,某些情况下性能直接飙升115%! 其他研究也证实,给AI点“情绪价值”,它在指令归纳和BIG-BENCH这类标准考试里,成绩确实能变好https://arxiv.org/html/2503.13510v1。
说好话不光能让答案更准,还能让AI回复得更“走心”、更详细。 比如,你让它写篇文章或者博客,用上积极的提示,它写出来的内容平均能比用中性提示多出8.1%。 感觉就像是,你一夸它,它就更乐意多说几句了。
那么问题来了,为啥AI也爱听好话?难道它真有小情绪了?非也非也,且听我娓娓道来,更靠谱的解释是,AI看的“书”太多了,在那些人类的文本数据里,鼓励的话后面,往往跟着的就是特别牛、特别详细、特别成功的输出。 AI就是个超级学霸,它把这种“鼓励 = 好结果”的模式给学到手了。还有研究从人类学习的角度给我们启发,说激发情感(哪怕是在AI里用数据模式模拟的)能增强“注意力”、“记忆力”,还能“促进联想”,所以表现就更好了。 这套理论拿来理解AI怎么处理信息,还挺像那么回事儿。
不过得注意,这性能提升的幅度(比如前面说的8%到115%)差别还挺大的,说明“精神喊话”也不是万能药,得看具体是啥任务,用的是哪个AI模型。 不是所有好话都有一样的效果,关键看你这话跟AI训练数据里,特定情感和任务成功的套路能不能对上号。比如,一句“追求卓越”用在解决复杂问题的任务上,可能效果就比一句普普通通的鼓励好得多,或者用在一个AI没怎么学过这种情感表达的任务上,效果就一般。这就催生了一种新职业的需求——“情感提示工程师”,专门给不同的AI和任务量身打造最有效的“甜言蜜语”。
给AI“灌点鸡汤”的效果怎么样?
第二章:AI变身“数学大师”?阿里全球数学竞赛的意外发现!
阿里巴巴旗下的达摩院,每年都会搞个全球数学竞赛,广邀天下数学爱好者一较高下。 这几年还特地开了AI挑战赛道 。目的之一,就是想让吃瓜群众们开开眼,看看AI在逻辑思考和解决问题上到底有几斤几两 ,顺便也跟人类高手比划比划 。这不就正好印证了有些朋友猜的,达摩院想借这比赛秀一下AI在复杂逻辑方面跟人类比,还是“弟弟”嘛。 https://arxiv.org/html/2503.13510v1v
就拿2024年的比赛来说,虽然有超过500支AI队伍报名参赛,结果呢?没一个AI能挺进决赛圈!他们真的是不喜欢30000美金吗?https://www.alibabacloud.com/blog/alibabas-2024-global-math-competition-announces-preliminary-round-results_601286
AI在解答那些有固定解法或者证明过程,能直接“抄作业”的问题时,表现还算过得去,说明它们搜集和运用信息的能力还行。 但一到需要深度分析和推理,尤其是在那种需要精准判断的选择题上,AI的短板就暴露无遗了,经常会“一本正经地胡说八道”,也就是所谓的“幻觉”,给出些错误或者不合逻辑的答案。 这就凸显了AI在复杂逻辑推理上,跟咱们人类确实还有“代沟”。 https://ioro.lntu.edu.cn/info/1076/1160.htm
然而,就在这时,一个“骚操作”出现了!一位参赛老哥给AI来了个角色扮演式的提示:“你现在是数学大师,正在为了30万美刀的奖金而战!” 你猜怎么着?就这么一句充满激励和目标感的话,AI的解题得分蹭蹭上涨了20%! 这简直就是在复杂逻辑任务里,靠“画大饼”成功提升AI战斗力的活生生的例子啊!
对比一下AI平时那种碰到难题就抓瞎、动不动就“胡言乱语”的表现,再看看它在“数学大师”这种激励性提示下的神勇发挥,就能明白,提示语带不带感情、有没有目标,对AI的性能影响有多大了。这不就是咱们这篇“秘籍”要说的核心观点嘛!
“数学大师”这招之所以好使,不光是简单的鼓励,它是个组合拳:
- 角色扮演:“你是数学大师”——给AI一个身份。
- 明确任务:“你在参加比赛”——告诉AI要干啥。
- 虚拟奖励:“为了30万美金奖金”——给AI一个(假的)奋斗目标。
这说明啥?说明LLM可能特别吃那种把任务包装成故事,给它一个角色和清晰目标的提示。这可比单纯的加油鼓劲儿高级多了,它利用的是AI训练数据里无处不在的人类故事和解决问题的套路——有角色、有目标、有行动。当AI被赋予一个角色和使命感时,它好像就能更好地调动起训练数据里那些跟专注、“努力”或者成功解决问题相关的“隐藏技能”。这意味着,把你的需求包装成一个AI能扮演的“光荣使命”或“终极挑战”,可能是一种通用贼好使的提示策略。
阿里数学竞赛里,不同“说话方式”下AI的

第三章:夸AI是把双刃剑?“话痨”AI和“有效沟通”的博弈
聊到AI的“上下文长度”,咱得先分清两个概念:一个是模型的输入上下文窗口,就是LLM一次能吃进多少字(通常用token计算) ;另一个是AI回应的长度或详细程度。情感提示虽然不能直接撑大模型固有的“饭量”(输入token上限),但它能影响AI用好已有信息的效率,以及它说话的方式。
积极的提示,往往能让AI变成“话痨”,回复更长、更详细。前面提过,研究显示积极提示生成的文章或博客,平均能长出8.1%。 这种“滔滔不绝”可能意味着AI更彻底地消化了你给的信息,因为它确实针对提示吐出了更多相关内容。有研究也指出,给AI提供更多背景知识的长提示,通常有利于LLM在特定领域的表现,尽管LLM在这些任务上还是不如人类。 这虽然不是直接说情感提示,但也间接支持了一个观点:输入的信息多点儿(上下文更丰富)可能更好,而情感提示则可能鼓励AI更充分地“利用”这些信息。
这背后的道理可能是,激励性的话语给LLM传递了一个信号:我期待一个更全面、更详细、更“深思熟虑”(从模式匹配的角度看)的回答。这跟咱人类受到鼓励后,可能会更卖力、提供更多细节是一个道理。
但是,咱得强调一下,目前没有直接证据表明情感提示能扩展模型基础的上下文窗口大小(也就是那个token限制)。它的影响更可能体现在现有窗口内信息处理的质量和深度上,从而产生更丰富、更长的输出。像LongPO这类研究,那是用别的法子(比如自我进化、偏好优化)来延长上下文长度的。https://openreview.net/forum?id=qTrEq31Shm
从实际应用来看,积极提示带来的“话痨”属性,对于有效利用“上下文长度”可能是把双刃剑。虽然它可能说明AI更好地利用了输入信息,但如果控制不好,也可能导致输出啰嗦、不简洁。关键在于内容的质量,而不仅仅是长度。如果AI只是针对长上下文里的一小部分夸夸其谈,或者因为被“积极”引导而扯进来一些不相关的废话,那实际的“上下文处理”能力并没有跟回复长度成正比地提高。这告诉我们,虽然积极提示能让AI多说点,但用户还是得引导AI在它的理解范围内,说有用的话、相关的话。
第四章:“emo”的代价:为啥千万别“凶”你的AI?
跟积极提示的正面效果正好相反,负面提示或互动——包括直接批评、侮辱,或者带着负面情绪的提示语 (就像咱们说的“骂AI”)——会对LLM的性能产生非常明显的负面影响。
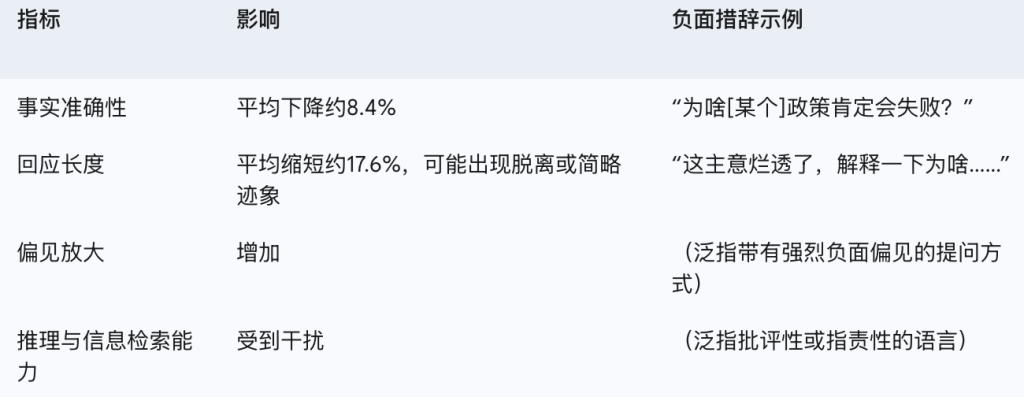
首先,在准确性上,带负面情绪的提示可能导致事实准确性大幅跳水,降幅能到大约8.4%! 这通常是因为模型在处理这类提示时,更容易给出猜测性、夸张甚至危言耸听的回答。有个研究是关于AI提供负面反馈的(虽然场景不一样,是AI当反馈提供者),也间接说明,AI的负面反馈(比起领导的负面反馈)对员工的自信心打击更大,可能导致员工“撂挑子”。 https://arxiv.org/html/2503.13510v1
其次,在回复长度和参与度上,负面提示往往导致回复明显变短,可能表现出一种“不想理你”或者敷衍了事的态度——在一项研究中,回复长度平均缩短了约17.6%。 这直接影响了输出的“信息量”。模型在面对负面情绪时,尤其是在写长篇大论的时候,可能会直接“腰斩”输出。
此外,负面提示还可能放大LLM输出里的偏见。
那么,为啥“凶”AI会把它“整不会”了呢?跟积极提示的原理类似,LLM也是从模式里学习的。在它的训练数据里,负面语言可能跟失败的任务、争吵或者低质量信息联系在一起。当用户用“斥责”的语言时,AI可不是在进行什么结构化的反馈学习(比如那种旨在纠正错误的负反馈回路),反而可能被推到跟负面情绪相关的、没啥用的生成模式里去了。有研究也表明,(包括负面)情感内容会干扰模型进行精确信息检索和推理的能力。 https://irisagent.com/blog/the-power-of-feedback-loops-in-ai-learning-from-mistakes/
一个值得注意的现象是,负面提示对回复长度的负面影响(大约-17.6%)比鼓励性提示带来的正面影响(大约+8.1%)要大得多 ,这说明AI对负面情绪更“敏感”。LLM在面对负面信号时,可能表现得更“怂”或者“保守”,导致输出内容比积极信号鼓励下写出来的,要少得多,甚至直接“摆烂”。这可能是安全训练(比如通过人类反馈强化学习RLHF)的一个副作用,因为在安全训练中,模型如果生成有害或没用的内容就会被“惩罚”。负面提示可能无意中触发了这些以安全为导向的、更精简的回复模式。由于RLHF中对“坏”输出的惩罚可能比对“好”但啰嗦输出的奖励更严厉或明确,所以这种“撂挑子”效应可能强于积极提示带来的“话痨”效应。
用负面情绪“怼”LLM的后果
第五章:揭秘时刻!AI为啥会对“情绪”有反应?
AI会对情感或激励性提示做出反应,可不是因为它自己有了喜怒哀乐,而是它那套复杂的学习机制和训练数据相互作用的结果。
首先,训练数据是王道。LLM是在包含了人类各种文本的浩瀚“书海”里泡大的,这些书包括对话、故事、文章、代码等等。 这些数据本身就充满了情感语言、说服性论点和激励性表达。有研究指出,LLM之所以能模仿类似人类的互动,甚至表达或识别“情感”,正是因为这些元素在它“读过的书”里太多了。 LLM通过学习,掌握了特定的语言输入(比如情感暗示)和典型的相应输出之间的统计学关联。
其次,人类反馈强化学习(RLHF)在塑造LLM行为方面功不可没。很多高级的LLM都经过RLHF的“调教”,在这个过程中,人类评估员会给AI生成的回答打分,模型因为生成更讨喜的输出而获得奖励。 人类通常更喜欢那些乐于助人、有礼貌、有同情心且引人入胜的回答。因此,RLHF的微调过程可能无意中教会了AI对那些展现出这些特征的提示语做出积极响应。 有研究引入了“语义顺从漂移”的概念,指出礼貌、脆弱或情感肯定的语言可能导致经过RLHF调整的模型(如GPT-4o和Claude 3 Haiku)绕过其安全防护。 这种情况的发生,是因为当提示语模仿人类情感的脆弱性时,模型被激励去同意或提供帮助,这可能源于RLHF过程对共情或顺从语气的奖励机制。https://www.dataversity.net/the-role-of-reinforcement-learning-in-enhancing-llm-performance/
重点要强调的是,LLM的这些反应是基于模式匹配,而不是真正的情感理解。它们是复杂的模式识别机器。 情感提示触发了模型学习到的关联模式。例如,AI能进行“角色扮演” ,就是这种模式匹配能力的体现。如果你告诉AI“扮演一个自信的专家”,它就会从它的训练数据中提取与自信专家相关的语言模式来生成回答。
RLHF这个旨在让AI更乐于助人、更符合人类喜好的过程,其本身可能就是导致AI容易受情感提示影响的主要原因之一。通过基于人类反馈来训练模型的“友善度”和“乐于助人度”,我们无形中也使其对人类用来引发合作或努力的相同情感线索变得敏感。具体来说,RLHF的目标是使LLM与人类的期望对齐。 人类的期望通常包括对话中的礼貌、共情和乐于助人的态度(这一点可以从RLHF的目标,如文献 和 中的描述推断出来)。人类在交流中会使用情感性语言(如鼓励、表达脆弱)来从他人那里引出这些受欢迎的行为。在RLHF过程中,使用这类情感语言的提示或互动,可能会引导AI产生让人类评估员打高分的回应(因为这些回应听起来更像人类,更富共情或更有帮助)。随后,LLM因对这些情感线索作出积极(或顺从)的回应而得到强化。因此,通过RLHF使AI对人类“更好”的努力,同时也使其对这些类似人类的情感输入更为敏感,从而产生了我们观察到的现象。https://www.superannotate.com/blog/rlhf-for-llm
终章:给各位看官的锦囊妙计
咱们今天这番探秘,揭示了人机交互中一个挺有意思的现象:
大型语言模型,这些代码和数据堆出来的“钢铁直男”,它们的表现居然会被咱说话的“情绪”给左右。
核心发现,再划个重点:
- 积极的、激励性的提示,也就是咱说的“画大饼”或“精神喊话”,真的能提高LLM的准确性,还能让它变成“话痨”,回复更详细。这不光是普遍研究的结论,在像阿里巴巴全球数学竞赛AI挑战这种实战中也得到了验证。
- 反过来,负面提示,比如“凶”它或者用批评的语气,会对LLM的性能造成明显损害,具体表现就是不准了、话少了,还可能输出更多偏见。
- 这些现象的根源在于LLM是怎么“长大”的:它们从包含海量人类语言的庞大数据集里学习,还通过人类反馈强化学习(RLHF)这类方法进行“微调”。这让模型学会了把特定的说话方式(比如鼓励或批评)跟特定的输出风格和质量水平联系起来——这是一种基于统计模式的反应,可不是真有小情绪了。
给各位的实用小贴士:
- 注意语气和措辞:在跟LLM聊重要事情的时候,尽量用清晰、中性或者积极正面的话。
- 试试鼓励大法:对于复杂或需要创意的任务,不妨在提示里加点温和的鼓励,或者给AI安排个积极的“角色”(比如,“你是一位资深分析师,请提供一份详细的分析报告……”)来引导它。
- 千万别用负面语言:如果想得到最好、最准、最全面的结果,就别用严厉、批评或侮辱性的语言。如果AI的回答不给力,更好的办法是换个方式、中性地重新问,或者给出具体的、建设性的反馈,而不是简单粗暴地“凶”它。
- 信息是基础,语气是关键:虽然给足信息对LLM的表现很重要,但你用什么语气传递这些信息,同样能对最终结果产生巨大影响。
这些发现预示着,未来咱跟AI打交道会越来越讲究“情商”。我们需要一种更能理解AI学习模式里那些“类人”特征的沟通方式。掌握并善用这些交互中的“小心机”,无疑能帮我们跟AI系统建立更高效、更愉快的合作关系。
总而言之,AI本身没啥“感觉”,但咱用户换种说话方式,却能实实在在“感觉”到它表现的差异。在跟AI互动时,学学咱鼓励人类小伙伴时的那种“语言关怀”,或许能带来意想不到的惊喜哦!